How to extend NLTK CorpusReader?

In this post we’ll extend NLTK CorpusReader class to load hacker news top stories dataset.
The whole code for this project is located at https://github.com/ClementBM/hackernews-eda
What’s NLTK for?
NLTK is a reference python library that enables you to play with human language data. It provides a suite of text processing tools for classification, tokenization, stemming, tagging, parsing, and semantic reasoning. It also gives an easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet and Penn Treebank. NLTK data package also includes various type of corpora such as lexicons and word lists, as well as tagged corpora. As a free, open source and community-driven project, it’s also quite easy to extend.
When dealing with natural language processing in python, NLTK is one of the oldest library still in use. Other well known libraries are spaCy, Standford Core NLP, pattern and Textblob. Natural Language Toolkit (NLTK), give us more than a good starting point to perform exploratory data analysis on textual data.
First, just a brief presentation of the chosen dataset.
HackerNews Dataset
Hacker News (sometimes abbreviated as HN) is a social news website focusing on computer science and entrepreneurship, similar to slashdot. In general, content that can be submitted is defined as “anything that gratifies one’s intellectual curiosity.”
The word hacker in “Hacker News” is used in its original meaning and refers to the hacker culture which consists of people who enjoy tinkering with technology.
Since HackerNews open its API, data is available in near real time.
Load the data
The real time of top 500 stories is available at https://hacker-news.firebaseio.com/v0/topstories.json.
Every story is retreived via the following end point https://hacker-news.firebaseio.com/v0/item/{item_id}.json, {item_id} being the id of the story in this case.
import json
import requests
from tqdm import tqdm
hn_topstories_url = (
"https://hacker-news.firebaseio.com/v0/topstories.json?print=pretty"
)
hn_get_item_url = (
"https://hacker-news.firebaseio.com/v0/item/{item_id}.json?print=pretty"
)
topstory_result = requests.get(hn_topstories_url)
topstory_ids = json.loads(topstory_result.text)
data = list()
for topstory_id in tqdm(topstory_ids):
result = requests.get(hn_get_item_url.format(item_id=topstory_id))
data.append(json.loads(result.text))
We use the loads() method from json module. The s in loads() means string. As requests.get return a string we use this method.
Save the dataset in a convenient format
Then we save the dataset on the disk as jsonl. Json line is a common json like format used to save corpus. Various python libraries use this format like HuggingFace, Scrapy and Spark among others.
Link to json line website specification
import pandas as pd
from pathlib import Path
TOPSTORIES_PATH = Path(__file__).parent / "hn_topstories.zip"
data_df = pd.json_normalize(data)
with open(file_path, "ab") as json_file:
data_df.apply(
lambda x: json_file.write(f"{x.to_json()}\n".encode("utf-8")),
axis=1,
)
NLTK has a reader class that takes a jsonl file as input. To spare the effort of creating a completely new class, I take inspiration from this one and save the base corpus file with the same format.
Integrate with NLTK
The nltk.corpus package defines a collection of corpus reader classes, listed here, which can be used to access the contents of a diverse set of corpora, listed here.
Each corpus reader class is specialized to handle a specific corpus, in a specific format. As the corpus of HackerNews Stories is not included in NLTK, we will build a CorpusReader class that handles this corpus in a jsonl format, taking inspiration from the Twitter corpus, where tweets are stored as a line-separated JSON.
In the following sections we see how to subclass ̀TokenizerI and CorpusReader.
Define a custom Tokenizer
To define a custom tokenizer, we need to create a class that inherits from nltk.tokenize.api.TokenizerI, an interface for tokenizing a string. Subclasses of TokenizerI must define tokenize() or tokenize_sents() (or both).
Here is a glimpse of the subclass StoryTokenizer where the tokenization logic resides.
class StoryTokenizer(TokenizerI):
def tokenize(self, text: str) -> typing.List[str]:
"""Tokenize the input text.
:param text: str
:rtype: list(str)
:return: a tokenized list of strings; joining this list returns\
the original string if `preserve_case=False`.
"""
safe_text = _replace_html_entities(text)
words = self.WORD_RE.findall(safe_text)
...
return words
![]() See the entire tokenizer code here
See the entire tokenizer code here ![]()
Define a custom Corpus Reader
To define a new CorpusReader, we need to create a class that inherits from nltk.corpus.reader.api.CorpusReader.
The base class CorpusReader defines a few general-purpose methods for listing and accessing the files that make up a corpus. Each corpus reader instance can be used to read a specific corpus format consisting of one or more files under a common root directory. Each file is identified by its file identifier, which is the relative path to the file from the root directory.
Hopefully, the following diagram will help you understand the NLTK class hierarchy.
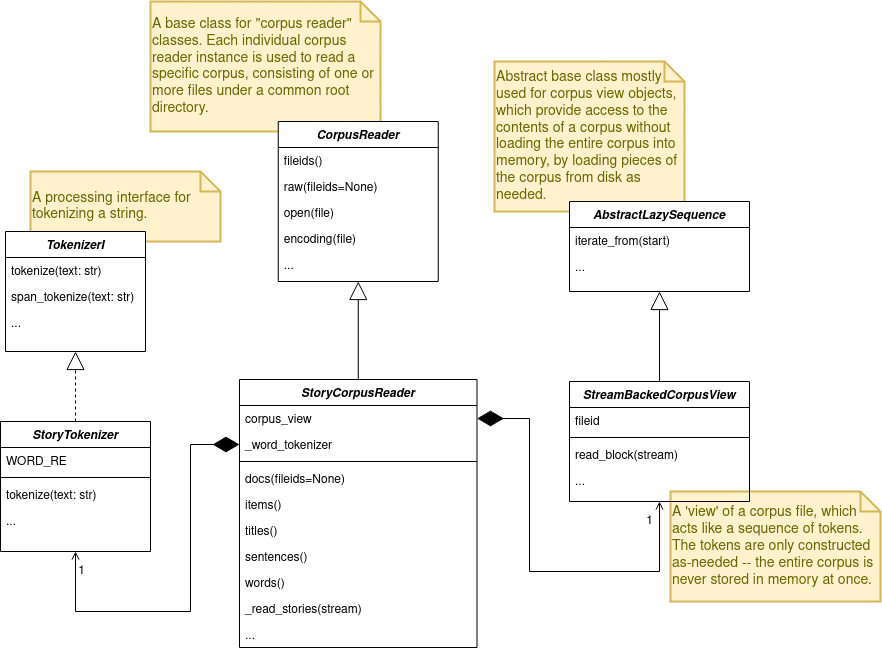
The two last following sections give more information on the data access methods of the corpus reader, and finally on the Corpus View classes.
Data Access Methods of the Corpus Reader class
Corpus Reader subclasses define one or more methods that provides ‘views’ on the corpus contents, such as words() (for a list of words) and parsed_sents() (for a list of parsed sentences). Called with no arguments, these methods will return the contents of the entire corpus. These methods can define one or more selection arguments, such as fileids or categories.
In general Corpus Reader gives us way to access properties of the corpus such as
- raw text
- a list of words
- a list of sentences
- a list of paragraphs
The signatures for data access methods often have the basic form:
corpus_reader.some_data_access(fileids=None, ...options...)
Some of the common data access methods, and their return types, are:
| Method | Return type |
|---|---|
| I{corpus}.words() | list of str |
| I{corpus}.sents() | list of (list of str) |
| I{corpus}.paras() | list of (list of (list of str)) |
| I{corpus}.chunked_sents() | list of (Tree w/ (str,str) leaves) |
| I{corpus}.raw() | str (unprocessed corpus contents) |
Corpus Views
A corpus view is an object that acts like a simple data structure (such as a list), but does not store the data elements in memory; instead, data elements are read from the underlying data files on an as-needed basis. NLTK’s corpus readers generally access the underlying data files using CorpusView.
In our case, we use the most common corpus view StreamBackedCorpusView which acts as a read-only list of tokens.
class StoryCorpusReader(CorpusReader):
corpus_view = StreamBackedCorpusView
By only loading items from the file on an as-needed basis, corpus views maintain both memory efficiency and responsiveness.
The heart of a StreamBackedCorpusView is its block reader function, which reads zero or more tokens from a stream, and returns them as a list. A very simple example of a block reader is:
def simple_block_reader(stream):
return stream.readline().split()
If you want to create your own corpus view see the NLTK documentation on corpus.
However, as the documentation said:
When writing a corpus reader for a corpus that is never expected to be very large, it can sometimes be appropriate to read the files directly, rather than using a corpus view.
Thanks for reading and follow the next blog post to explore the HackerNews story dataset with the CorpusReader.