How to train an agent to play Connect Four with Reinforcement Learning?

In this post I’ll demonstrate how to train an agent to play connect four using reinforcement learning. Then I’ll show you how to integrate it in a gradio application and finally making it public by deploying it on Hugging Face space.
If you want to learn more about the underlying mechanisms of reinforcement learning, you’d better look somewhere else. A good starting point would be Deep Reinforcement Learning by Udacity course or the RL section in Hands-On Machine Learning by Aurélien Geron. This being said, in the RL field, a (software) agent observes a virtual environment, and takes actions given the environment state. In return the environment assigns a reward to the agent. The objective of the agent is to learn to act in a way that will maximize its expected rewards over time.
With RL, an agent can be trained to:
- control a robot
- regulate house temperature as a thermostat
- drive a car in an intelligent transportation system (ITS)
- make recommandation in a recommender system
Reinforcement learning is different than traditional machine learning technics such as supervised or unsupervised learning. Supervised Learning tries to predict or classify y, given x. Unsupervised Learning tries to simplify y, given x. Whereas Reinforcement Learning tries to choose the “best” actions given an uncertain environment.
All the code for this project is available at Hugging Face, and you may be able to clone the repository with the following command:
git clone https://huggingface.co/spaces/ClementBM/connectfour
Table of contents
Technical Stack
Poetry
Poetry is a packaging and dependency management system in python powered by Vercel. It makes virtual environments easy to handle and it’s multi-platform: Linux, macOS and Windows.
You just declare the libraries your project depends on and Poetry manage installs and updates for you.
Poetry has also a lockfile to ensure repeatable installs (on your CI server, or other developer machines), and consistency when deployed on production machines.
Here you can access a template repository (with poetry) that I built. It’s a good starting point if you want to give poetry a try.
Ray & RLlib
Ray is an open source framework powered by Anyscale that provides a simple, universal API for building distributed systems and tools to parallelize machine learning workflows. The framework is a large ecosystem of applications, libraries and tools dedicated to machine learning. It also integrates with multiple libraries for distributed execution: scikit-learn, XGBoost, TensorFlow, PyTorch, Hugging Face, spaCy, LightGBM, Horovod, …
RLlib is part of the Ray ecosystem as a reinforcement learning library. It offers high scalability and a unified API for a variety of applications. RLlib natively supports TensorFlow, TensorFlow Eager, and PyTorch, but most of its internals are framework agnostic. RLlib has a huge number of state-of-the-art RL algorithms implemented.
Some well known industry actors already use Ray:
- at Microsoft, ChatGPT developer OpenAI is using Ray for training large language models
- at Shopify to build Merlin, the Shopify’s machine learning platform
- at Uber for large scale deep learning training and tuning
Petting Zoo
PettingZoo is a Python library for conducting research in multi-agent reinforcement learning. It’s powered by the Farama foundation, a nonprofit organization working to develop and maintain open source reinforcement learning tools.
It has different types of environment:
- Multi-player Atari 2600 games (cooperative, competitive and mixed sum)
- Classic: Classical games including card games, board games, etc.
- …
Agent, Environment and Training
Algorithm class is the cornerstone of RLlib components. The Algorithm has a policy, a neural network model that tries to maximize the expected sum over all future rewards.
The model/policy maps an observation of the environment to an action \(\Pi(s(t)) \rightarrow a(t)\).
An Algorithm also sets up its rollout workers and optimizers, and collects training metrics. In RLlib a rollout is an episode, or a game of connect four in our case.
The following diagram illustrates the iterative learning process (from RLlib documentation):
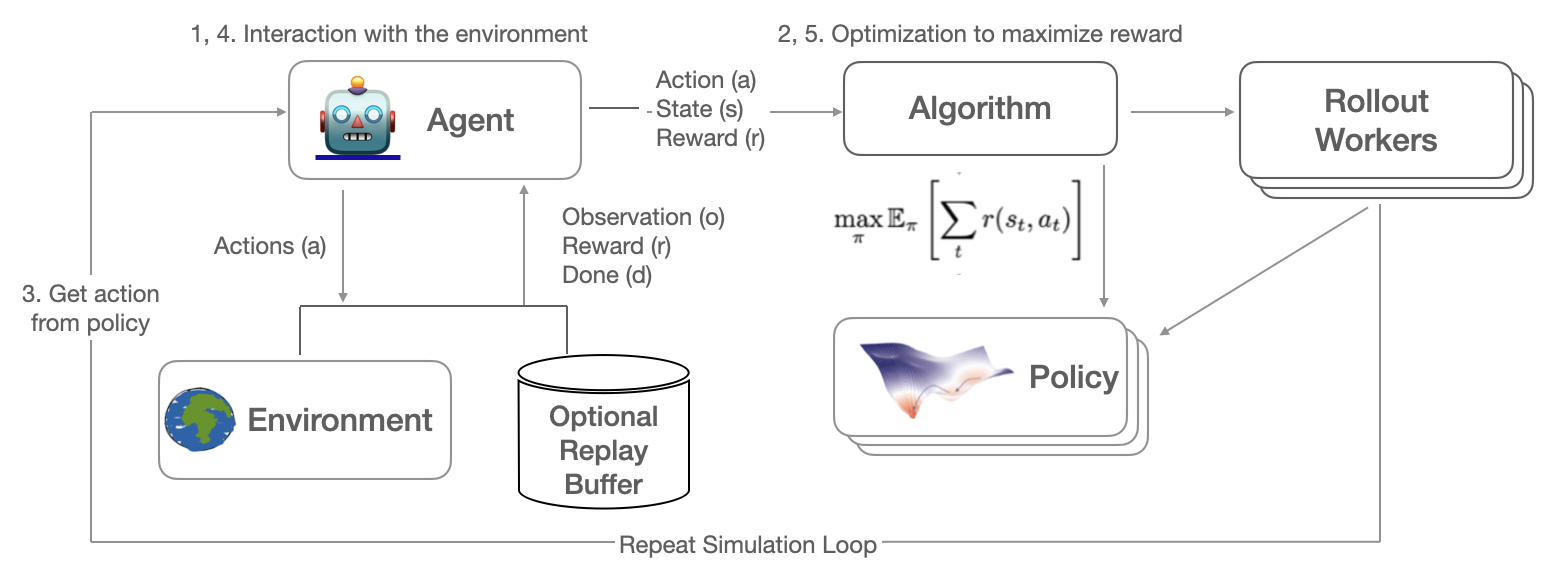
Proximal Policy Optimization (PPO) Agent
Actor-Critic algorithm is a family of RL algorithms that combine policy gradients with Deep Q-Networks. An agent of this family contains two neural networks: a policy network and a DQN. The DQN is formed normally, learning from the experiences of the agent. The policy network learns differently than in normal Policy Gradient. Instead of estimating the value of each action by going through several episodes, summing the discounted future rewards for each action, then normalizing them, the actor agent relies on the action values estimated by the critical DQN. It’s a bit like an athlete (the agent) who learns with the help of a coach (the DQN).
A2C is part of the Actor-Critic family. With A2C several agents learn in parallel, by exploring different copies of the environment. At regular intervals, each agent forwards certain weight updates to a master network and then fetches the latest weights from that network. Each agent contributes to the improvement of the master network and benefits from what the other agents have learned. Additionally, instead of estimating Q-Values, DQN estimates the benefit of each action, which makes the training more stable. Model updates are synchronous, so gradient updates are performed in larger batches, allowing the model to make better use of GPU power.
The PPO algorithm is based on A2C which cuts the loss function to avoid excessively large weight updates (source of instabilities). PPO is a simplification of the previous TRPO algorithm. In April 2019, the OpenAI PPO-based AI agent called “OpenAI Five”, beat the world champions at the Dota 2 multiplayer game.
The RLlib implementation of PPO’s clipped objective supports multiple SGD passes over the same batch of experiences. RLlib’s multi-GPU optimizer pins this data into GPU memory to avoid unnecessary transfers from host memory, improving performance over a naive implementation.
Environment wrapper around PettingZoo Connect Four
Connect Four is a 2-player turn-based game. The players drop their tokens in a column of a standing grid, where each token fall until it reaches the bottom of the column or is stopped by an existing token. Players have to connect four of their tokens vertically, horizontally or diagonally. The game ends when a player has made a sequence of 4 tokens or when all columns have been filled, or if a player makes an illegal move.
The PettingZoo Connect Four game environment has to be wrapped before using it with RLlib API.
Once it’s converted into an rllib MultiAgentEnv we can finally train our agents.
The connect four environment is described as follow:
| Property | Value | Description |
|---|---|---|
| Agent | [“player_0”, “player_1”] | Two players. |
| Action | [0..6] | The list of all possible actions, the action space. |
| Observation | (6, 7, 2) [0,1] | A complete description of the environment, nothing is hidden in the state space. In this game, what’s the players see (the observation state) is the same as the state space. Nothing is hidden. |
| Reward | [-1,0,1] | The reward is the feedback the agent receives per action. In this game, rewards are sparse, which means they are given when the game ends. Winner receives 1, looser receives -1, the ties get 0, cheater gets -1 and the other 0 |
The RLlib environment wrapper has some limitations:
- All agents must have the same
action_spacesandobservation_spaces - Environments should be positive sum games, that is agents are expected to cooperate to maximize reward. Indeed standard algorithms don’t perform well in highly competitive games.
from pettingzoo.classic import connect_four_v3
# define how to make the environment
env_creator = lambda config: connect_four_v3.env(render_mode="rgb_array")
# register the environment under an rllib name
register_env("connect4", lambda config: Connect4Env(env_creator(config)))
I had to tweak the PettingZooEnv class to make it work with the connect_four_v3 environment:
- I override the
reset()method of PettingZooEnv - as well as the
render()method
@PublicAPI
class Connect4Env(PettingZooEnv):
"""Inherits from PettingZooEnv wrapper"""
def reset(self, *, seed: Optional[int] = None, options: Optional[dict] = None):
# In base class =>
# info = self.env.reset(seed=seed, return_info=True, options=options)
self.env.reset(seed=seed, options=options)
return (
{self.env.agent_selection: self.env.observe(self.env.agent_selection)}, {},
)
def render(self):
# In base class =>
# return self.env.render(self.render_mode)
return self.env.render()
Legal Action Mask
As the rules of connect four sometimes prohibit the players from playing in a certain column of the grid, the observation dictionary contains a action_mask element, where the legal moves available to the current player are defined. The action_mask is a binary vector where each index of the vector represents whether the action is legal or not.
To make the policy support the action mask, the policy’s model need to be adapted. For this, I merely copy/paste the ActionMaskModel defined in RLlib’s examples.
from ray.rllib.models.torch.fcnet import FullyConnectedNetwork
from ray.rllib.utils.torch_utils import FLOAT_MIN
from ray.rllib.utils.framework import try_import_torch
torch, nn = try_import_torch()
class Connect4MaskModel(TorchModelV2, nn.Module):
def __init__(self, obs_space, action_space, num_outputs, model_config, name, **kwargs):
# ... init stuffs ...
self.internal_model = FullyConnectedNetwork(
orig_space["observation"],
action_space,
num_outputs,
model_config,
name + "_internal",
)
def forward(self, input_dict, state, seq_lens):
# Extract the available actions tensor from the observation.
action_mask = input_dict["obs"]["action_mask"]
# Compute the unmasked logits.
logits, _ = self.internal_model({"obs": input_dict["obs"]["observation"]})
# Convert action_mask into a [0.0 || -inf]-type mask.
inf_mask = torch.clamp(torch.log(action_mask), min=FLOAT_MIN)
masked_logits = logits + inf_mask
# Return masked logits.
return masked_logits, state
def value_function(self):
return self.internal_model.value_function()
A league of opponents
Connect Four is competitive game in which players want to win the most games. As the standard algorithms aren’t expected to work well in competitive environment, it is not recommended to train both player’s policies at once. The main idea is to frequently make frozen version of the learning policy, and then add the frozen version to the league of opponents. As a starting point, I also added several basic heuristics for the learning policy to play against. Some of which acts randomly or plays the same column each turn.
class AlwaysSameHeuristic(HeuristicBase):
_rand_choice = random.choice(range(7))
def _do_compute_actions(self, obs_batch):
return [self.select_action(x) for x in obs_batch["action_mask"]], [], {}
def select_action(self, legal_action):
legal_choices = np.arange(len(legal_action))[legal_action == 1]
if self._rand_choice not in legal_choices:
self._rand_choice = np.random.choice(legal_choices)
return self._rand_choice
To manage the league of opponent’s policies, I adapted the callback class defined in this rllib example. My SelfPlayCallback class looks like this:
def create_self_play_callback(win_rate_thr, opponent_policies, opponent_count=10):
class SelfPlayCallback(DefaultCallbacks):
def __init__(self):
super().__init__()
self.current_opponent = 0
self.opponent_policies = deque(opponent_policies, maxlen=opponent_count)
self.policy_to_remove = None
self.win_rate_threshold = win_rate_thr
self.frozen_policies = {
"always_same": AlwaysSameHeuristic,
"linear": LinearHeuristic,
"beat_last": BeatLastHeuristic,
"random": RandomHeuristic,
}
def on_train_result(self, *, algorithm, result, **kwargs):
result["win_rate"] = self.get_win_rate(result)
if result["win_rate"] > self.win_rate_threshold:
if len(self.opponent_policies) == self.opponent_policies.maxlen:
self.policy_to_remove = self.opponent_policies[0]
new_pol_id = self.get_new_policy_id()
self.add_policy(new_pol_id, algorithm)
else:
print("Not good enough... Keep learning ...")
result["league_size"] = len(self.opponent_policies) + 1
def on_evaluate_end(self, *, algorithm, evaluation_metrics, **kwargs):
if self.policy_to_remove is not None:
algorithm.remove_policy(
self.policy_to_remove,
policy_mapping_fn=self.create_policy_mapping_fn(),
)
self.policy_to_remove = None
algorithm.workers.sync_weights()
def add_policy(self, new_pol_id, algorithm):
if new_pol_id in list(self.frozen_policies.keys()):
new_policy = algorithm.add_policy(
policy_id=new_pol_id,
policy_cls=self.frozen_policies[new_pol_id],
policy_mapping_fn=self.create_policy_mapping_fn(),
)
else:
new_policy = algorithm.add_policy(
policy_id=new_pol_id,
policy_cls=type(algorithm.get_policy("learned")),
policy_mapping_fn=self.create_policy_mapping_fn(),
)
learned_state = algorithm.get_policy("learned").get_state()
new_policy.set_state(learned_state)
algorithm.workers.sync_weights()
def get_new_policy_id(self):
new_pol_id = None
while new_pol_id is None:
if np.random.choice(range(6)) == 0:
new_pol_id = np.random.choice(list(self.frozen_policies.keys()))
else:
self.current_opponent += 1
new_pol_id = f"learned_v{self.current_opponent}"
if new_pol_id in self.opponent_policies:
new_pol_id = None
else:
self.opponent_policies.append(new_pol_id)
return new_pol_id
def get_win_rate(self, result):
main_rew = result["hist_stats"].pop("policy_learned_reward")
opponent_rew = result["hist_stats"].pop("episode_reward")
won = 0
for r_main, r_opponent in zip(main_rew, opponent_rew):
if r_main > r_opponent:
won += 1
return won / len(main_rew)
def create_policy_mapping_fn(self):
def policy_mapping_fn(agent_id, episode, worker, **kwargs):
return (
"learned"
if episode.episode_id % 2 == int(agent_id[-1:])
else np.random.choice(list(self.opponent_policies))
)
return policy_mapping_fn
return SelfPlayCallback
Training Loop with Ray Tune
Finally I define a configuration for the PPO algorithm and then use the power of ray.tune to manage the training loop.
config = (
(
ppo.PPOConfig()
.environment("connect4")
.framework("torch")
.training(model={"custom_model": Connect4MaskModel})
)
.multi_agent(
policies={
"learned": PolicySpec(),
"always_same": PolicySpec(policy_class=AlwaysSameHeuristic),
"linear": PolicySpec(policy_class=LinearHeuristic),
"beat_last": PolicySpec(policy_class=BeatLastHeuristic),
"random": PolicySpec(policy_class=RandomHeuristic),
},
policy_mapping_fn=select_policy,
policies_to_train=["learned"],
)
.callbacks(
create_self_play_callback(
win_rate_thr=args.win_rate_threshold,
opponent_policies=["always_same", "beat_last", "random", "linear"],
opponent_count=15,
)
)
.evaluation(evaluation_interval=1)
)
Then I use ray tune api, and call the fit() method.
results = tune.Tuner(
"PPO",
param_space=config.to_dict(),
checkpoint_config=air.CheckpointConfig(
num_to_keep=10,
checkpoint_at_end=True,
checkpoint_frequency=10,
checkpoint_score_order="max",
)
).fit()
You can retrieve the best checkpoint by calling first get_bet_result() method and its checkpoint property:
results.get_best_result(metric="win_rate", mode="max")
Ray monitoring with Prometheus/Grafana
Ray dashboard is a powerful way to monitor Ray application. You can monitor system-level metrics, the ray nodes, and resources status (gpu, cpu, heap).
This article or this one show you how to setup the monitoring system. Here are the main steps:
- Download
prometheusand unzip the archive - Once
Rayhas been running with export metrics enable (ray[default]), you should find aprometheus.ymlconfig file at/tmp/ray/session_latest/metrics/prometheus/ -
cd <prometheus install directory> ./prometheus --config.file=/tmp/ray/session_latest/metrics/prometheus/prometheus.yml - Access the Prometheus server from the default url at http://localhost:9090
- Download Grafana
- Start the Grafana server with the default configuration file
cd <grafana install directory> ./bin/grafana-server --config /tmp/ray/session_latest/metrics/grafana/grafana.ini web - Access the Grafana server from the default url at http://localhost:3000
Finally, have a look at the time series graph from the Ray dashboard. You can visualize numerous utilization metrics such as CPU/GPU, memory usage, disk usage, object store usage, or network speed.
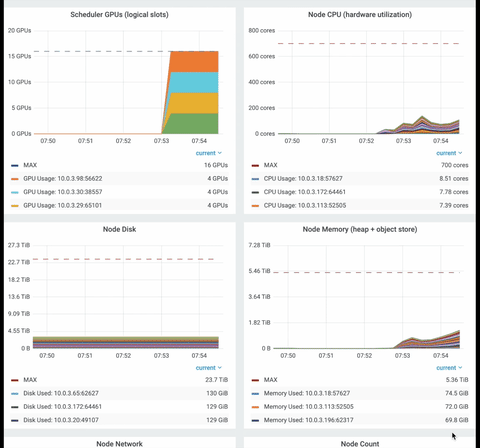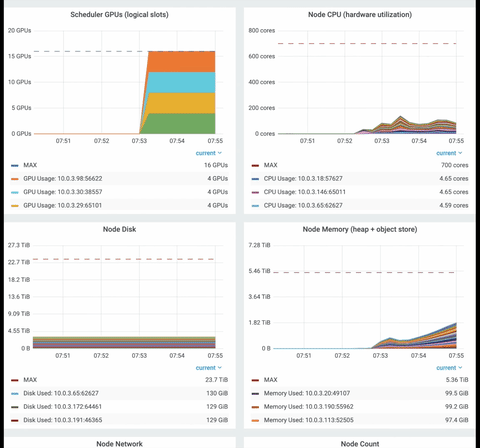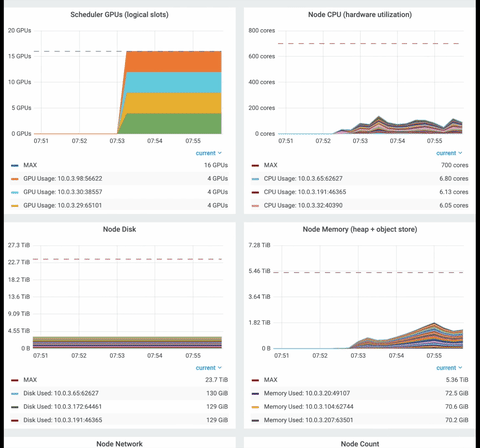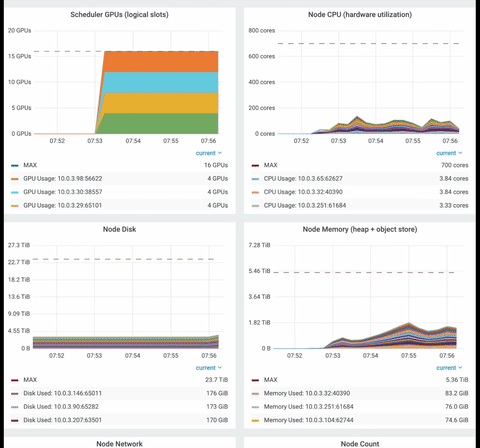
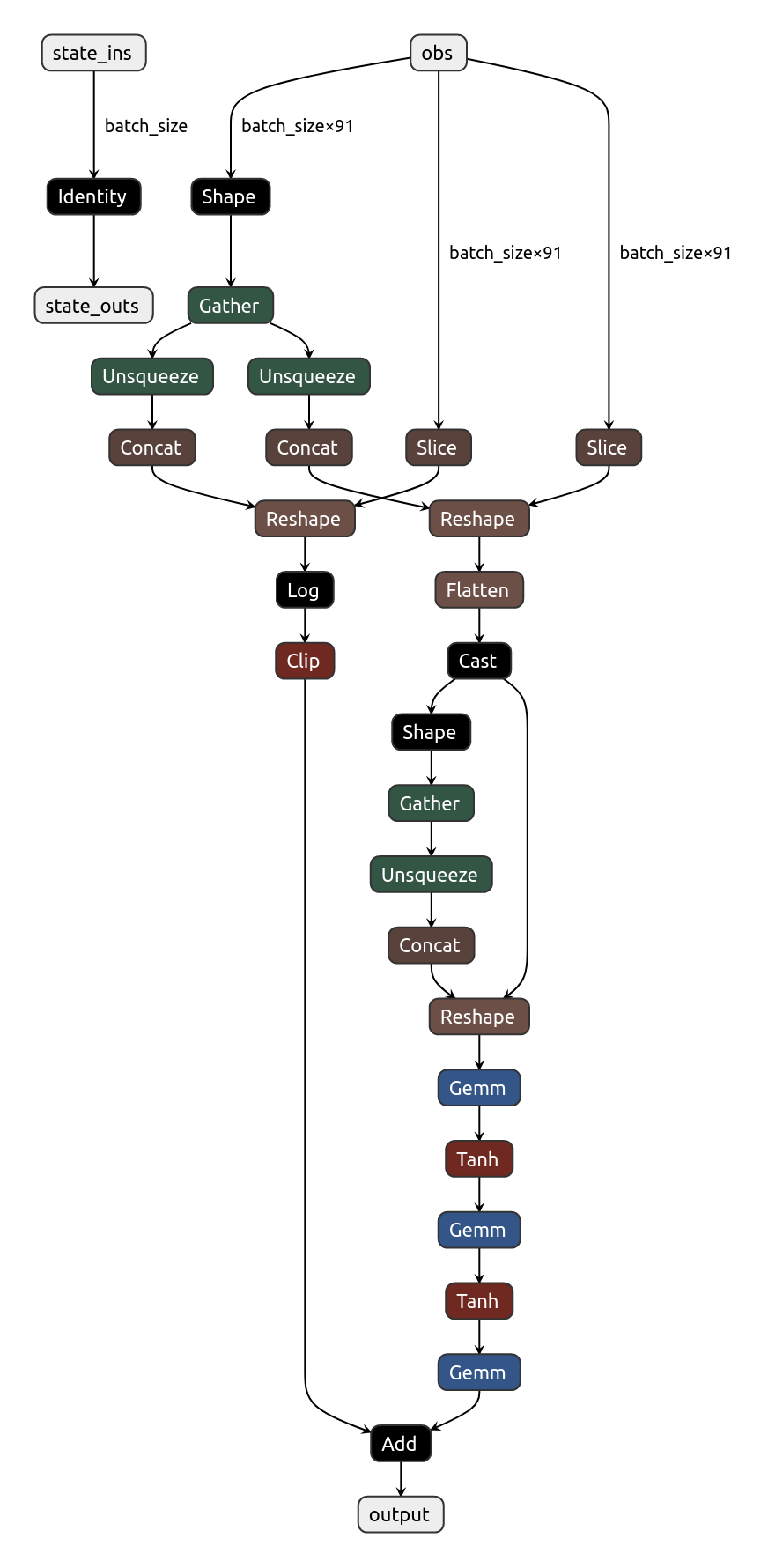
Export the policy’s model as ONNX
Exporting the model in an open format make it easier to share and decouple from the training environment. Open Neural Network Exchange (ONNX) is an open format built to represent machine learning models.
With RLlib you can export the model if you configure the AlgorithmConfig like this:
config.checkpointing(export_native_model_files=True)
And then saving the model as onnx:
algo = Algorithm.from_checkpoint(analysis.best_checkpoint)
ppo_policy = algo.get_policy("learned")
ppo_policy.export_model("models", onnx=11)
Now the model is easily shareable, and you can even visualize it with the online NETRON app.
Integration and deployment (free of charge)
Demo Interface with Gradio App
Gradio App is an open-source library which enables you to build an interface to show your experiments with a couple lines of code. Gradio is an easy way to demo your machine learning project with a web interface.
In my case I use the gradio.Blocks() low-level API, that you can use to build web apps with flexible layouts and data flows:
import gradio as gr
gr.Blocks()
...
The latest code I used for the Connect Four Gradio App is available here in the app.py file.
Once you’ve created an interface, you can permanently host it on Hugging Face’s servers and share it with anyone.
Create a Space at Hugging Face
Hugging Face Spaces are Git repositories that host application code for Machine Learning demos. You can build Spaces with Python libraries like Streamlit or Gradio or using Docker images.
In our case we select Gradio space SDK
Then to tell the space which dependencies it needs, you may export the requirements.txt file with poetry:
poetry export -f requirements.txt --output requirements.txt --without-hashes
Git Large File Storage (LFS)
Last thing before pushing your repository to HF Spaces is to setup git LFS.
If you have large model files (>10MB), or file with specific extensions like .onnx, they should be tracked with git-lfs.
You can initialize Git LFS by downloading it from git-lfs.github.com. And then run this install command:
./install.sh
> Git LFS initialized.
Once installed, you can set up Git LFS for your user account by running
git lfs install
When you use Hugging Face to create a repository, Hugging Face automatically provides a list of common file extensions for common Machine Learning large files in the .gitattributes file, which git-lfs uses to efficiently track changes to your large files.
*.pkl filter=lfs diff=lfs merge=lfs -text
*.onnx filter=lfs diff=lfs merge=lfs -text