Easy exploratory data analysis on hacker news stories

This post is about corpus exploration with NLTK, it’s the continuation of the first post on How to extend NLTK CorpusReader? Working with NLTK is a great way to learn how to use the toolkit while discovering more about NLP in general.
Table of contents
- Text class wrapper
- Sliceable Text
- Concordance
- Find all regex
- Token distribution
- Removing stop words
- Plot frequency distribution
- Lexical dispersion plot
- Go further
- Sources
First we load our corpus with the CorpusReader class creating in the previous post
story_corpus = StoryCorpusReader()
We then use a NLTK native class called nltk.book.Text. The code for this post is located in this file.
Text class wrapper
According to the documentation, the Text class is a wrapper around a sequence of simple (string) tokens, which is intended to support initial exploration of texts. Its methods perform a variety of analyses on the text’s contexts and display the results.
A Text is typically initialized from a given document or corpus. In our case we use words() from the StoryCorpusReader class.
from nltk.text import Text
story_text = Text(story_corpus.words())
Text can work as a collection. That is, you can access a token via an integer index.
Sliceable Text
You can also slice the collection as shown below. The following two lines give the same results
story_text[3:5]
story_text.tokens[3:5]

Concordance
If you want to explore the context of certain term/token, concordance is a great way to have a quick view.
The concordance() function print the surrounding of a chosen word. Word matching is not case-sensitive.
story_text.concordance("language")

This output is not exactly what we would except as the titles are concatenated, some concordances overlap between two titles.
Find all regex
If you want something more granular than concordance you can use the findall() function. It enables you to filter the result of the search based on regular expression. It finds instances of the regular expression in the text. The text is a list of tokens, and a regexp pattern to match a single token must be surrounded by angle brackets.
For instance, if you want to spot the word “Google” preceded by two words of any kind:
story_text.findall("<.*><.*><Google>")

Token distribution
It’s also easy to find the most common tokens of the corpus. You can use the vocab() function
story_text.vocab().most_common(10)
vocab() output a dictionary that has a token as a key and the number of occurence as a value. The value is the number of times the token appears in the corpus.

To have a better idea of the most frequent word of this corpus, we would like to remove stop words, that is, words that are common across all corpora.
Removing stop words
story_vocab = story_text.vocab()
stop_words = set(stopwords.words("english"))
removable_vocab_keys = []
for vocab_key in story_vocab.keys():
if vocab_key.casefold() in stop_words:
removable_vocab_keys.append(vocab_key)
for removable_vocab_key in removable_vocab_keys:
story_vocab.pop(removable_vocab_key)
Plot frequency distribution
After removing the most frequent words, we look at the distribution of the most frequent words.
plt.figure(figsize=(18, 12))
story_vocab.plot(20, cumulative=False, percents=False, show=False)
plt.xticks(rotation=45)
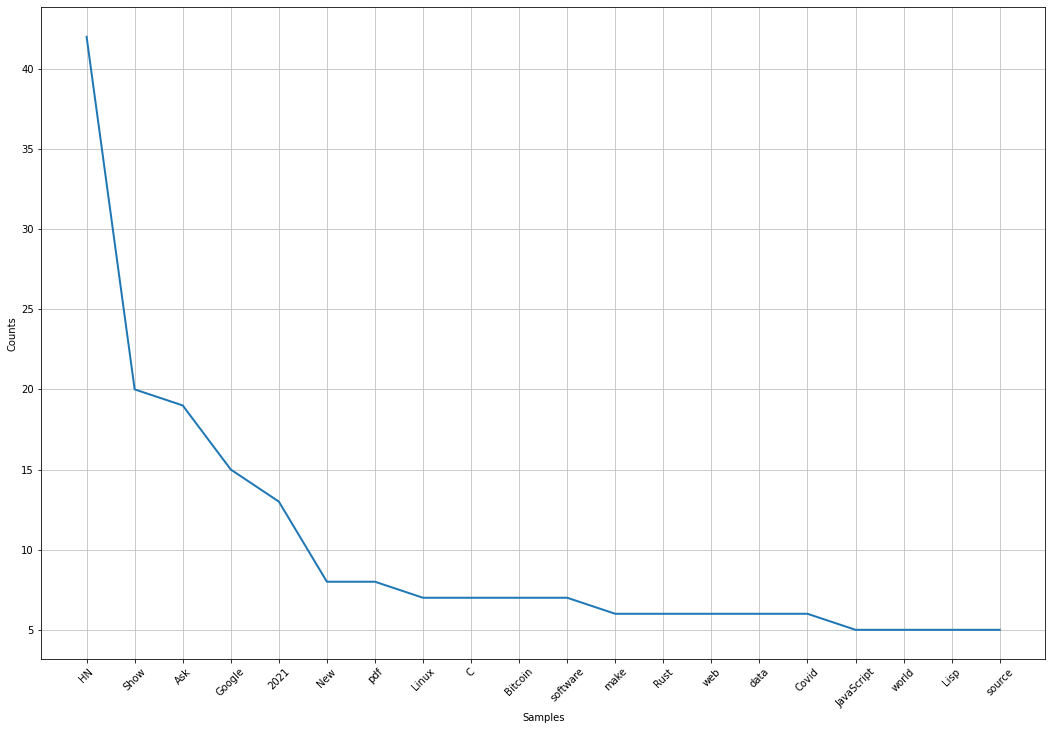
story_text.plot() is a shortcut for story_text.vocab().plot(). Be careful of aliasing, i.e. changing story_vocab will also modify the outcome of story_text.vocab(). The vocab() being an accessor of the underlying private property _vocab.
Lexical dispersion plot
This plot shows the distribution of the words through the text. Indices of words are on the horizontal axis.
story_text.dispersion_plot(
[
"Rust",
"Python",
"JavaScript",
"C",
]
)

Go further
If you wish to write a program which makes use of these analyses, then you should bypass the Text class, and use the appropriate analysis function or class directly instead.